突发,华为首个开源大模型来了
今时不同往日,华为一改当年“绝不开源”的态度。
一、华为态度两极反转,从“绝不开源”到主动开放
短短两年,华为对盘古大模型的态度,来了个180 度大转弯。
还记得2023年,华为云开发者大会上,华为常务董事、华为云CEO张平安正式发布盘古3.0大模型时,明确表示盘古大模型不会开源。

图源:抖音
做出这一决定,在当时对华为来说并不是任性而为。
彼时,国际科技竞争激烈,“卡脖子”风险高悬头顶。
而华为盘古大模型走的是全栈自研路线,从底层芯片到模型算法,每一步都是华为自己研发出来的,没有采用任何开源技术。
并且,据张平安介绍,盘古大模型定位是行业赋能,深度应用在矿山、电力等众多领域,涉及大量客户机密数据,开源可能会带来数据泄露的安全隐患。
直到今天,2025年6月30日,华为画风突变,正式宣布开源盘古70亿参数的稠密模型以及盘古Pro MoE 720亿参数的混合专家模型,还一并开源了基于昇腾的模型推理技术。

图源:微信
今时不同往日,华为的这一决策背后,是外部环境变化、技术成熟度的提升以及对生态建设的深远考量。
此次开源的盘古70亿参数的稠密模型,具有参数量适中、性能均衡、部署门槛较低的特点。它在智能客服、知识库等多种场景中均可应用,能够为不同行业的企业提供高效、灵活的解决方案。
模型的开源,意味着更多的开发者和企业可以基于它进行二次开发和创新,从而推动人工智能在更多领域的应用落地。
而盘古Pro MoE 720亿参数的混合专家模型,更是“王炸”级别的存在。
它独创MoGE(分组混合专家)架构,通过动态激活专家网络,仅需160亿激活参数,就能媲美千亿级模型的性能。
比如在SuperCLUE 2025年5月的开源模型排行榜上,盘古Pro MoE 72B名列前茅,与阿里的Qwen3-32B(Thinking)一齐成为千亿以下超强性能的国产开源大模型。
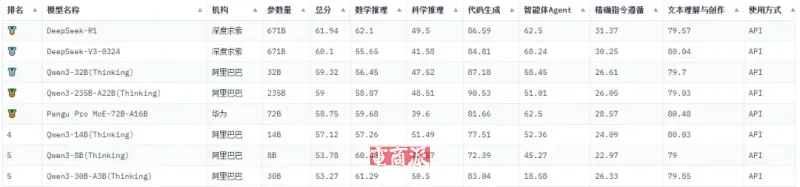
图源:SuperCLUE官网
再说说基于昇腾平台的模型推理技术。
据华为方面介绍:“我们以前很少对外发声,盘古也没有开源,所以大家对昇腾算力具体的情况不是特别了解,对模型的情况也不了解,外界就充满了猜疑。甚至认为昇腾训练不出来先进的大模型。”
“昇腾算力能够训练出世界一流的大模型,训练高效率,推理高性能,系统高可用。第三方模型迁移到昇腾上可以做到:Day0迁移,一键部署。”
值得注意的是,华为此前曾强调盘古大模型与ChatGPT不在同一轨道。
ChatGPT 走的是 Transformer 架构的“暴力美学”路线,更偏向消费级对话场景;而盘古采用Encoder - Decoder架构,在多模态融合和物理推理上优势明显,聚焦工业、气象等垂直领域。
就拿气象预测来说,盘古的气象模型预测速度比传统方法快1万倍,还被欧洲中期天气预报中心采用,这是两者的本质区别。
二、华为开源背后的战术考量
其实,今年以来,中国AI 行业掀起了一股开源热潮,多家企业都改变了闭源的思路,其中就包括大家耳熟能详的OpenAI,还有百度。
要说是什么让这些大佬纷纷转变态度,DeepSeek的横空出世居功至伟。
秉持着开源理念的DeepSeek用更小的训练成本却带来了性能媲美国内外顶尖模型的DeepSeek-R1,并将推理模型向全球数十亿用户普及,给了以往坚持“闭源才是王道”的企业足够的心灵冲击。

图源:抖音
在这样的背景下,华为此次宣布开源盘古大模型,可以说是顺应潮流,但其背后也有自己的考量。
华为官方表示,开源盘古大模型是践行昇腾生态战略的关键举措,旨在推动大模型技术的研究与创新发展,加速人工智能在千行百业的应用与价值创造。
从华为的角度来看,这一决策确实能为其带来不少潜在好处。
一方面,盘古模型深度依赖昇腾芯片,开源后企业若想更好的落地应用,就需要采购昇腾服务器或云服务,这能大大加速昇腾芯片的规模化渗透,抢占国产算力市场;
图源:开源开发者平台GitGo
另一方面,不同规模的开源模型能吸引不同需求的开发者,例如盘古70亿模型适合高校科研,而Pro MoE模型则更吸引企业开发者。
通过开源吸引更多ISV(独立软件开发商)加入昇腾生态,形成“模型-工具-应用”的正向循环;
再者,开源能够加速人工智能技术的普及和应用。随着盘古大模型的开源,企业和开发者又多了一种以低的成本获取强大AI技术实力的方式,从而推动人工智能在更多行业的应用和落地。
此外,开源还能够提升华为在国际AI领域的影响力和话语权。一举多得,何乐而不为?
三、中国AI百花齐放,百家争鸣
如今的中国AI 领域,可谓是百花齐放、百家争鸣,几家领先的人工智能企业都在各自赛道上发力,不断推陈出新。
阿里通义千问持续升级迭代。先是在5月9日发布通义千问2.5版本,相比之前,理解能力、逻辑推理、指令遵循、代码能力分别提升9%、16%、19%、10%。
前几天又发布了多模态统一理解与生成模型Qwen VLo,支持文本、图像、视频多模态理解与生成,在电商领域,还能自动生成商品详情页和营销文案,效率提升300%,妥妥的“全能王”。
图源:微博
字节跳动豆包也是动作频频。6月11日,火山引擎发布豆包大模型1.6、豆包视频生成模型Seedance 1.0 pro、豆包语音播客模型,并升级Agent开发平台等AI云原生服务。
而同样在今天,豆包公众号宣布“深入研究”功能在App、网页端、电脑版开启测试,不断拓展应用场景,力争成为场景化的“爆款制造机”。
图源:豆包
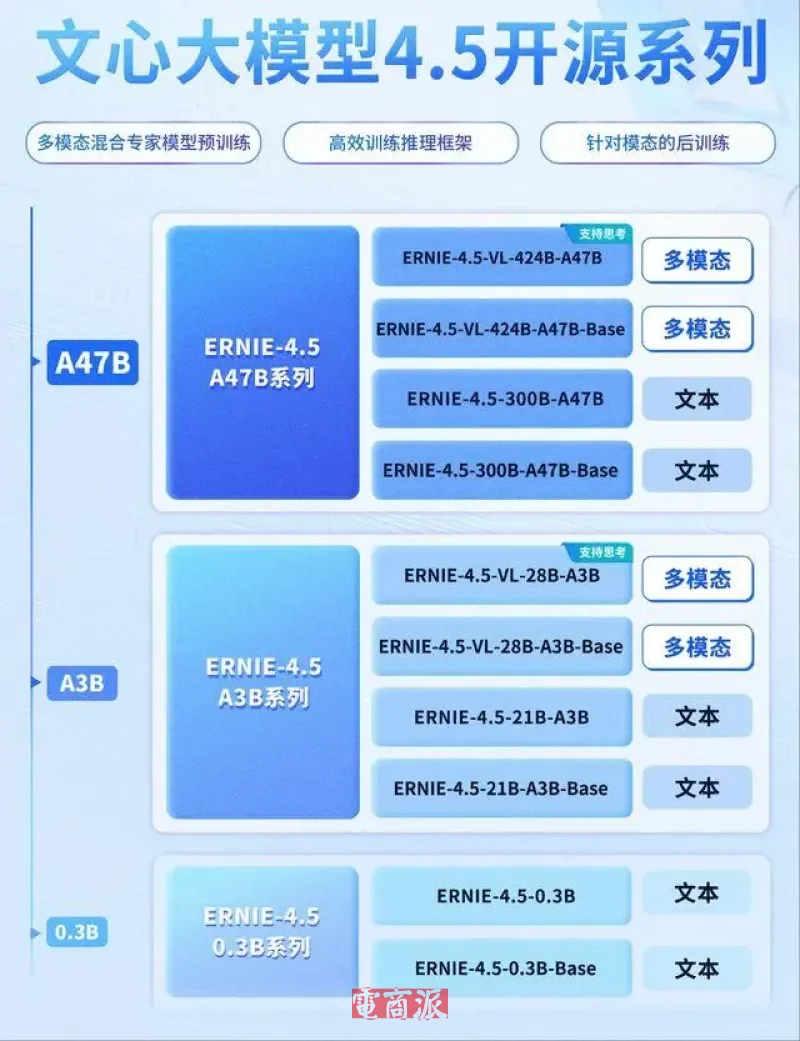
百度文心一言同样在今天放出大招,正式开源文心大模型4.5系列10款模型,涵盖47B、3B激活参数的混合专家(MoE)模型,与0.3B参数的稠密模型等,并实现了预训练权重和推理代码的完全开源。
文心大模型4.5系列在多文本和多模态基准测试中达到了SOTA水平(当前最高水平),尤其在指令遵循、世界知识记忆、视觉理解和多模态推理任务上表现出色。
图源:微博
当然,华为的盘古大模型的最新成果也并没有停留在上述提到的盘古Pro MoE 72B。
6月20日,盘古大模型迎来了5.5版本的发布,该版本的自然语言处理(NLP)能力比肩国际一流模型,并在多模态世界模型方面做到全国首创。
盘古大模型5.5包含了五大基础模型,分别面向NLP、多模态、预测、科学计算、CV领域,进一步推动了大模型成为行业数智化转型的核心动力。
盘古Ultra MoE、盘古Pro MoE、盘古Embedding等一系列模型的推出,不仅展示了华为在AI领域的深厚技术积累,也为行业提供了更多高效、实用的解决方案。
更为关键的是,盘古Ultra MoE是718B(7180亿)参数的MoE深度思考模型。也就是说,华为甚至还小藏了一手,估计后续会有更重磅的开源。
所以DeepSeek呢?上面提到这么多优秀企业的发展进度,DeepSeek怎么样了?
随着2025年已经过去了一半,AI行业的蓬勃发展让人们对DeepSeek R2的期待愈发强烈。DeepSeek的上一次更新,还停留在上个月。
5月底,DeepSeek R1迎来重磅更新,这次更新增强了模型的思维深度和推理能力,提升了响应速度和对话稳定性,减少了“遗忘设定”或“跑题”的情况。详情可以关注我们的《》这篇文章。
而据多方消息透露,DeepSeek-R2的训练成本有望降至0.07美元/百万token,推理速度还能比R1快上2倍,并支持代码、数学、法律等专业领域深度推理。
一旦发布,必将再次震撼整个行业。
2、电商号平台仅提供信息存储服务,如发现文章、图片等侵权行为,侵权责任由作者本人承担。
3、如对本稿件有异议或投诉,请联系:info@dsb.cn


